Related Projects
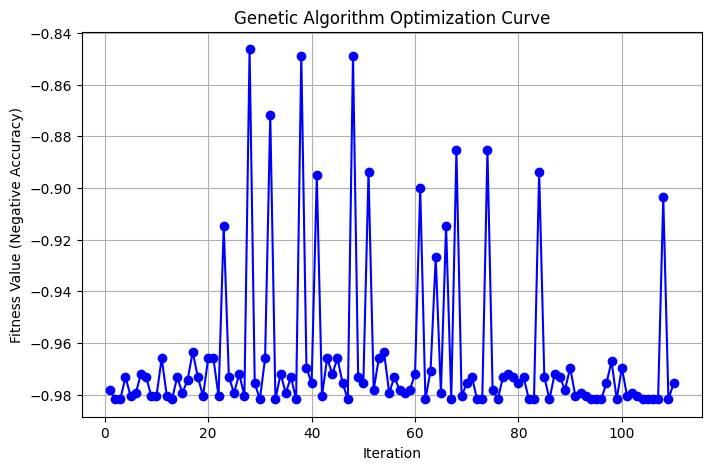
Optimizing Heart Disease Prediction Models Using Genetic Algorithm and Neural Architecture Search
Machine Learning
View Details
Loads and inspects an Excel dataset, then reads and parses a text file to extract specific customer names and monetary values using regular expressions.
The notebook first imports pandas and matplotlib to load the clean_canada_data.xlsx Excel file into a DataFrame and display its first few rows for a quick overview. It then switches to text processing: using Python’s built-in open and the re module, it reads Iphone_Order.txt, extracts the full name of the second customer whose name starts with “S” and ends with “er”, finds all dollar-amount patterns (e.g. “$1,499.99”), and demonstrates splitting the text at punctuation. Finally, it shows the first five records with proper header columns to illustrate basic data-wrangling and pattern-matching techniques .
Machine Learning
View Details