مشاريع ذات صلة
قد تهمك أيضاً هذه المشاريع

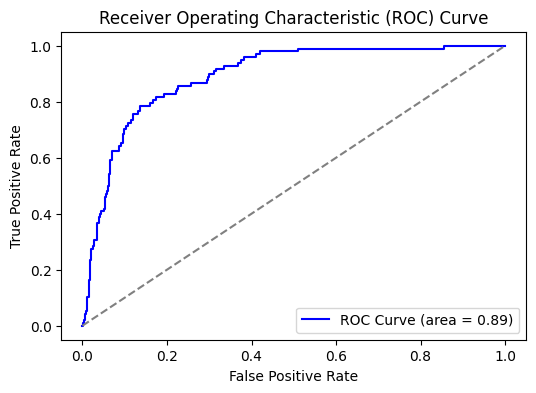
تنفيذ تصنيف k لأقرب الجيران، والذي تم ضبطه عبر البحث الشبكي، لتحديد المعاملات الاحتيالية في مجموعة بيانات بطاقات الائتمان.
يقرأ المشروع مجموعة بيانات "Credit_Card_Fraud_Detection.csv" باستخدام pandas، ويفحص بنيتها، ويطبق StandardScaler لتطبيع الميزات. يُقسّم البيانات إلى مجموعات تدريب واختبار، ثم يستخدم GridSearchCV للعثور على أفضل معلمات KNeighborsClassifier الفائقة. يوضح رسم بياني لمعدل الخطأ مقابل k خيارات الضبط، وتشمل مقاييس التقييم النهائية درجة الدقة، وتقرير التصنيف، ومصفوفة الارتباك.
استعرض ملف الخاص بالمشروع أدناه أو اطلب نسخة منه.
قد تهمك أيضاً هذه المشاريع